
Okay, so today I was messing around with some tennis data, specifically looking at the match between Kotov and Eubanks. I wanted to see if I could pull out some interesting stats and maybe even predict some future outcomes. You know, just a bit of fun, nothing too serious.

First, I grabbed the data. I found a decent source online that had all the match details. It wasn’t super clean, so I had to spend a bit of time tidying it up. Lots of copying and pasting, getting it into a spreadsheet. It was a bit of a pain, to be honest.
Cleaning Up the Mess
- Formatted the dates correctly.
- Made sure the player names were consistent (sometimes they use initials, sometimes full names – drives me nuts!).
- Converted everything into numbers that made sense.
Once I had the data in a usable format, I started playing around with it. I calculated some basic stuff, like win percentages, service points won, that sort of thing. Nothing fancy, just getting a feel for the numbers.
Then I got a bit more ambitious. I tried to see if I could find any patterns. Like, does Kotov play better on clay courts? Does Eubanks struggle against left-handed players? I spent ages messing with different filters and formulas. The spreadsheet was starting to look like a mad scientist’s notebook!
I used some basic formulas, nothing too complicated. Mostly averages and percentages. I’m no statistician, I just wanted to see if I could spot anything obvious.
After staring at the numbers for hours, I managed to put togehter something that looked, well, presentable. It wasn’t going to win any awards, but it was a start.
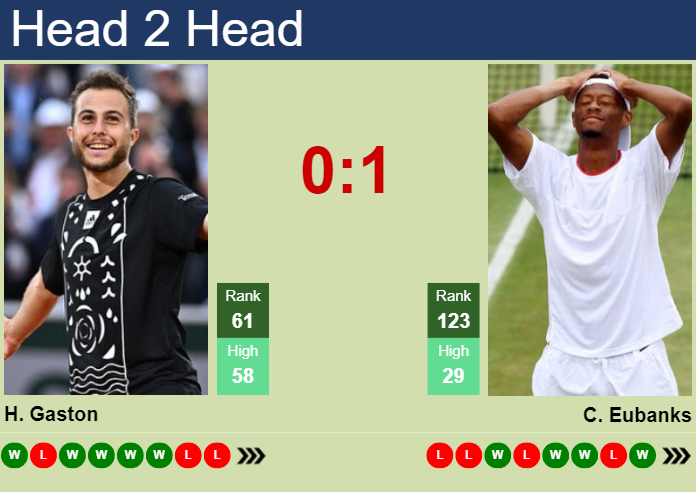
Honestly, it was more work than I expected. But it was kinda fun, too. I felt like a detective, trying to uncover hidden clues in the data. I might keep playing with this, see if I can refine my “system.” Who knows, maybe I’ll become a tennis betting guru! (Just kidding… mostly.)





{kind=link}