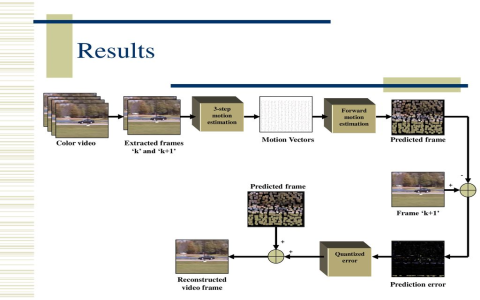
Alright, so I recently decided to really dive into this thing called inter prediction. You know, the way videos get squished down by looking at other frames. I always kinda knew the theory, but I wanted to get my hands dirty and see how it actually works, like, in practice.
I started off pretty basic. Grabbed a couple of consecutive frames from a simple video clip I had lying around. Just two static images, basically picture A and picture B that came right after it. My thinking was, okay, picture B must look a lot like picture A, right? Especially if not much is moving.
So, the first thing I did was try to figure out how to represent picture B using picture A. I picked a small block of pixels in picture B. Let’s say, a little square in the top-left corner. Then, I started looking around in picture A for a block that looked almost exactly the same.
I wrote a really simple script, nothing fancy, just something to help me compare. It went through picture A, block by block, comparing each one to my target block from picture B. The comparison was crude – just subtracting the pixel values and summing up the differences. Whichever block in picture A gave the smallest difference, I called that the ‘match’.
Finding the Matches
This part took a while. My script was slow. And finding a perfect match? Almost never happened. There were always small differences – maybe lighting changed slightly, or there was noise, or maybe something moved just a tiny bit.
This was the core idea clicking for me: you don’t need a perfect match. You just need the best possible match you can find nearby. Once you find it, you don’t store the actual pixels of the block in picture B. Instead, you just store two things:
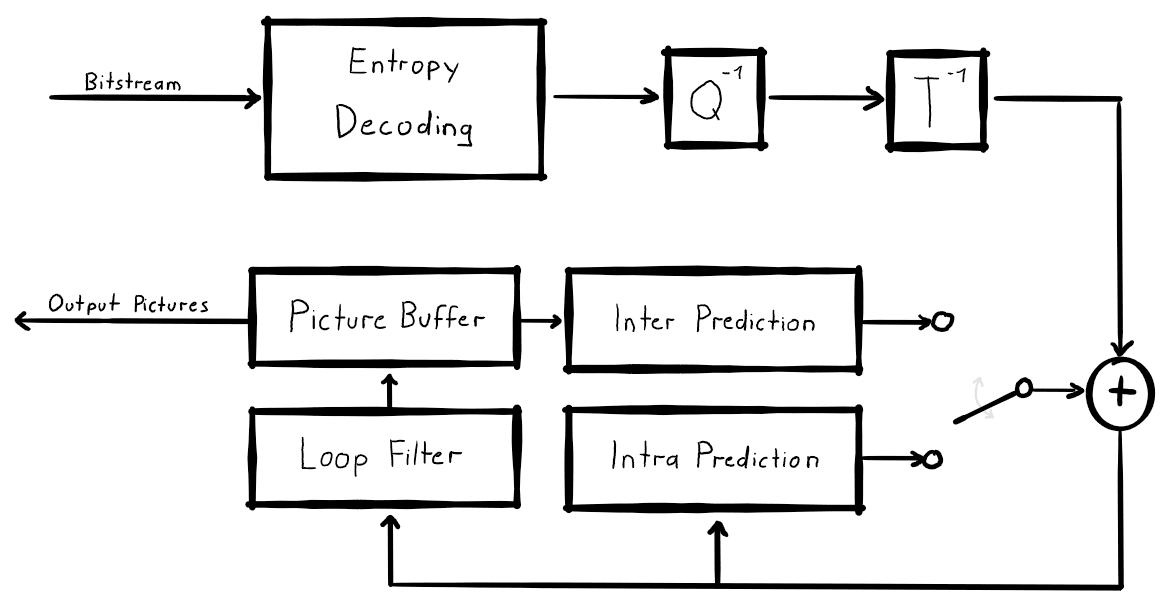
- Where the best matching block is located in picture A (like, ‘go 5 pixels right and 2 pixels down from this spot’).
- The difference between the block in picture B and the matching block in picture A.
Usually, this difference data is much smaller than storing the whole block again. And if the match is really good, the difference is tiny, almost zero! That’s where the compression comes from.
Dealing with Movement
Okay, static frames were one thing. Then I tried it with a video where something was actually moving. Like a ball rolling across the screen. This made things way more interesting, and harder.
My simple script had to search a much wider area in picture A to find the block from picture B, because the ball moved. The ‘best match’ wasn’t in the same spot anymore. It was shifted over. So, the ‘where’ information (that pointer to the block in picture A) became super important.
I spent a lot of time just visually stepping through frames and trying to predict where a block would end up. It felt like playing detective with pixels. Sometimes I’d find a good match, other times the block changed too much (maybe it rotated, or half of it got covered by something else). That’s when the ‘difference’ data becomes larger, or maybe the encoder decides it’s just better to encode the block directly without referencing picture A.
Putting it Together (Sort Of)
I didn’t build a full video encoder or anything, nowhere close. My goal was just to understand the process of finding those matches and representing blocks using references to other frames. I hacked together some visual tools to highlight the blocks I was comparing and show the calculated differences.
What I learned:
- Inter prediction is really clever. It saves a ton of data by not repeating stuff.
- Finding the ‘best’ match is the tricky part. Faster movement, changing lighting, things appearing or disappearing – they all make it harder.
- There’s a trade-off. Searching a wider area in the reference frame might find a better match, but it takes more time and computation.
- The ‘difference’ data is key. Even with a good match, you often need to store a little correction.
It was a fun exercise. Definitely gave me a better appreciation for what’s happening inside video codecs. It’s not magic, just a lot of smart searching and comparing. Still feels like there’s a ton more complexity under the hood, but doing it manually, even crudely, made the basic idea stick.






{kind=link}